Incorporating world knowledge to document clustering via heterogeneous information networks
Chenguang Wang, Yangqiu Song, Ahmed El-Kishky, Dan Roth, Ming Zhang, and Jiawei Han.
In Proc. 2015 ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining (KDD 2015).
paper code data slides video
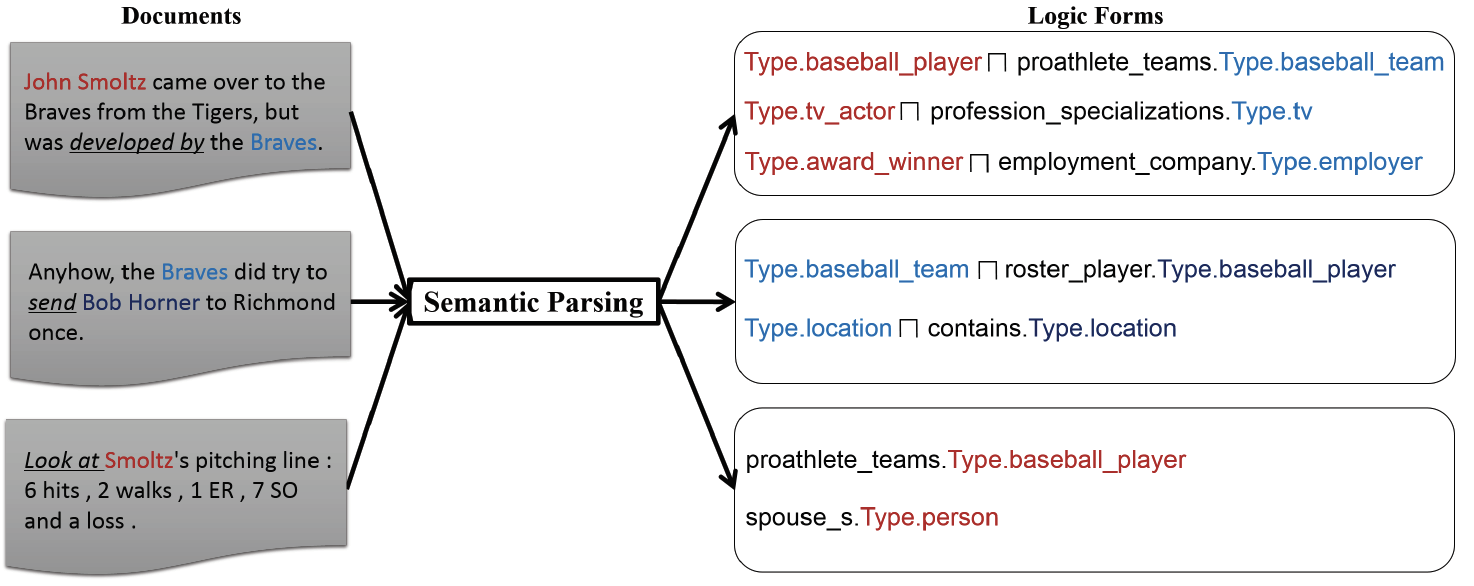
We provide three ways to specify the world knowledge to domains by resolving the ambiguity of the entities and their types, and represent the data with world knowledge as a heterogeneous information network.